
Scripting: Work Smarter, Not Harder
September 13, 2018Multi-stage Docker Builds
November 13, 2018Group concatenation condenses items from specified columns into a list of values.
This is a bit easier to explain with visuals. Let’s begin.
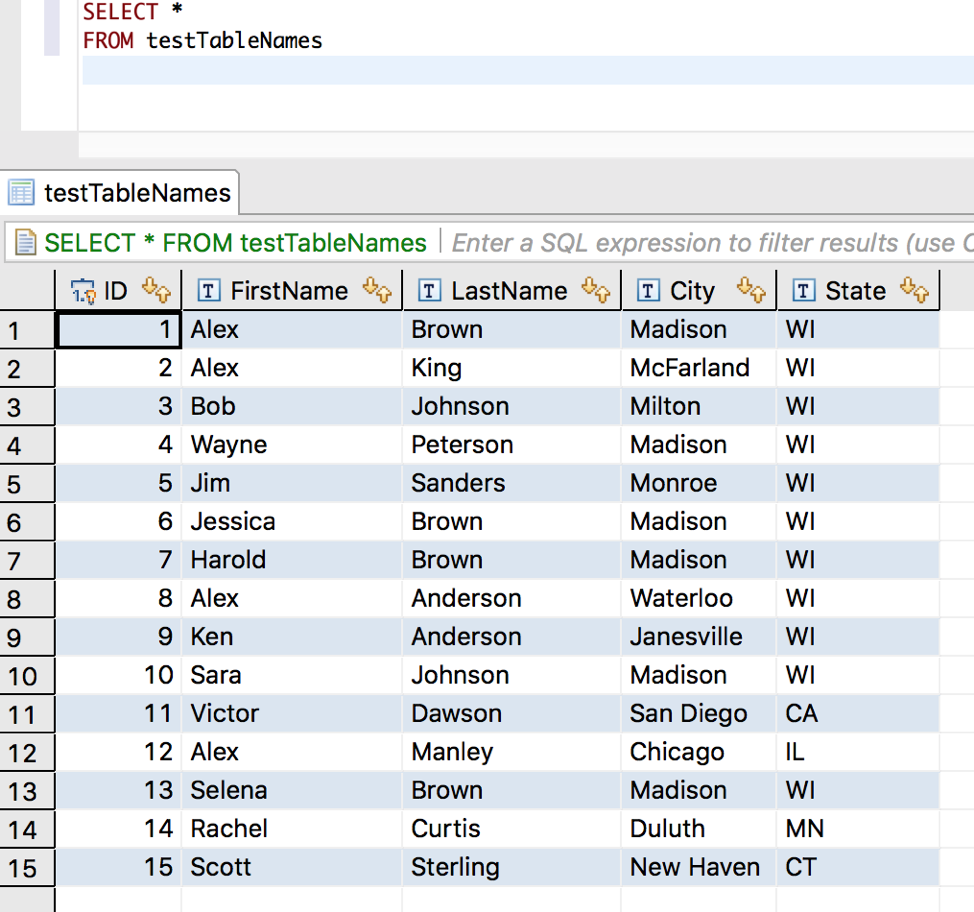
There are a several different ways a person could use this table of information where group concatenation is helpful. To get started, let’s just throw GROUP_CONCAT on a first name selection:

Notice that it is listing the first name of every single row but smashed down into a single, comma separated list. No sorting, no filtering, just add each row to the pile. This is what GROUP_CONCAT does when there are no restrictions at play. We are telling it to concatenate everything in the column without looking at anything else.
Now let’s say the goal is to return a list of unique first names. Just like you would use DISTINCT to select unique row patterns, you can use DISTINCT within the GROUP_CONCAT:

Same result but this time it ignores anything it already has in the list. It also alphabetized the names for us too. Neato.
What if you need a list of everyone named ‘Alex’ along with last names? You can include multiple columns within the GROUP_CONCAT to expand on the list items. In the following example, we are grabbing first name, adding a space, then last name for each list item. The SEPARATOR keyword allows you to tell the GROUP_CONCAT how to separate its list items. If you get a little creative, you could build a query that returns ready to display lists depending on your needs:

Ok… That’s all fine and dandy for single cell returns. What if we need a proper query with multiple rows? What does that look like?
For the next example our goal is to see the unique cities among the crowd of people in our database. Also, we need to pair the cities up with the state they belong to. I also aliased the GROUP_CONCAT selector as City List for a better column name! Have a look:
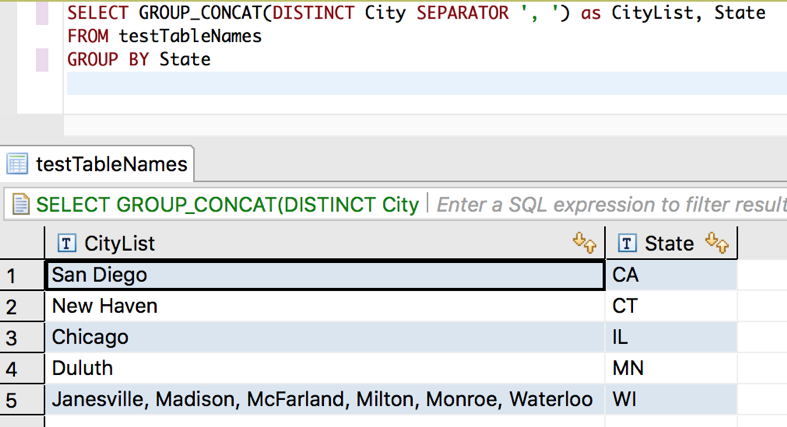
Pretty awesome eh? In one simple query we have a city list for each state. Note that we had to include a GROUP BY statement at the bottom for State. Any time you use GROUP_CONCAT in the selection clause, any selected column that is not making use of it will need to be included in a GROUP BY clause. This informs the query as to what and where it can smash things together. Another example to demonstrate:
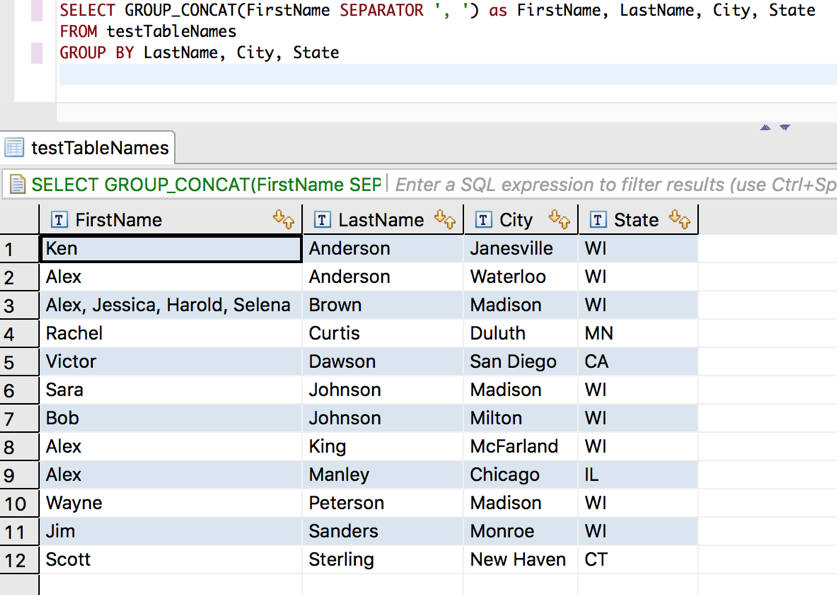
By looking at this, you can see that the query looks for matches in last name, city, and state before performing the GROUP_CONCAT on first names. The sequence in the GROUP_BY part is similar to telling the query how to sort the groups once they are formed. Notice that we are getting last names alphabetically, then city, then state. What if we select 2 different GROUP_CONCAT items? Now we will group them by location, then show the list of unique first and last names.

Cool stuff eh? While some of these uses may have alternate solutions, it is good to be aware of this function whenever you are looking to condense your data for specific columns. A real world example I used this one for was a data table that linked answer IDs to question IDs. Every question could have multiple answers, so there were a lot of different rows with the same question ID but different answers. A one-to-many relationship. By group concatenating the answers column in my query it allowed me to simply return each question as a row with the list of answers all contained in that single row. Performance improved significantly and it cleaned up the code quite a bit! Part of this performance improvement was the simplification of the application code, but also because the database can perform these operations far quicker than the application code could.
These are just a few examples to get you started. Add it to your toolbox and keep an eye open for any situation where it can make your life and code simpler!
Cheers!


{kind=link}
{kind=link}